
この記事はもともとに投稿されました TheNewStack.
マット・ザンドとジム・サリバン
Kubernetesはコンテナ化されたソリューションです。ポッドと呼ばれる仮想化されたランタイム環境を提供します。ポッドは、仮想ランタイム環境を提供するために1つ以上のコンテナーを収容します。 Kubernetesの重要な側面は、ポッド内のコンテナ通信です。さらに、Kubernetesネットワークを管理する重要な領域は、コンテナポートを内部および外部に転送して、ポッド内のコンテナが相互に適切に通信できるようにすることです。このような通信を管理するために、Kubernetesは次の4つのネットワークモデルを提供しています。
- コンテナ間の通信
- ポッド間通信
- ポッドからサービスへの通信
- 外部から内部へのコミュニケーション
この記事では、ポッド内のコンテナーがネットワーク化して通信する方法を示すことにより、コンテナー間の通信について詳しく説明します。
ポッド内のコンテナ間の通信
1つのポッドに複数のコンテナがあると、それらが互いに通信するのが比較的簡単になります。彼らはいくつかの異なる方法を使用してこれを行うことができます。この記事では、i-共有ボリュームとii-プロセス間通信の2つの方法について詳しく説明します。
I-Kubernetesポッドの共有ボリューム
Kubernetesでは、ポッド内のコンテナ間でデータを共有するためのシンプルで効率的な方法として、共有Kubernetesボリュームを使用できます。ほとんどの場合、ポッド内のすべてのコンテナと共有されるホスト上のディレクトリを使用するだけで十分です。
Kubernetes Volumesを使用すると、データはコンテナの再起動後も存続できますが、これらのボリュームの有効期間はポッドと同じです。これは、ボリューム(およびボリュームが保持するデータ)が、そのポッドが存在する限り正確に存在することを意味します。そのポッドが何らかの理由で削除された場合、同じ置換が作成されたとしても、共有ボリュームも破棄され、最初から作成されます。
共有ボリュームを持つマルチコンテナポッドの標準的な使用例は、一方のコンテナがログまたはその他のファイルを共有ディレクトリに書き込み、もう一方のコンテナが共有ディレクトリから読み取る場合です。たとえば、次のようにポッドを作成できます。
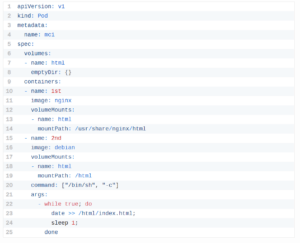
この例では、htmlという名前のボリュームを定義します。そのタイプはemptyDirです。これは、ポッドがノードに割り当てられたときにボリュームが最初に作成され、そのポッドがそのノードで実行されている限り存在することを意味します。名前が示すように、最初は空です。最初のコンテナはNginxサーバーを実行し、共有ボリュームがディレクトリ/ usr / share / nginx / htmlにマウントされています。 2番目のコンテナはDebianイメージを使用し、共有ボリュームがディレクトリ/ htmlにマウントされています。 2番目のコンテナは、共有ボリュームにあるindex.htmlファイルに現在の日付と時刻を毎秒追加します。ユーザーがポッドにHTTPリクエストを送信すると、Nginxサーバーはこのファイルを読み取り、リクエストに応じてユーザーに転送します。 こちら 同様のKubernetesトピックの詳細を読むのに適した記事です。
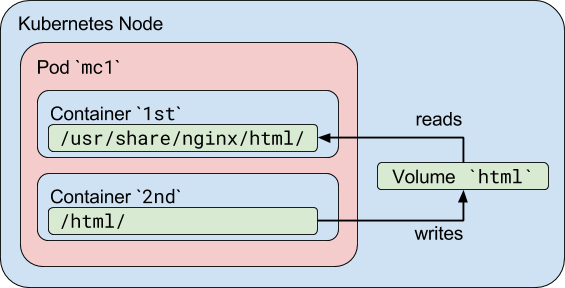
ポッドが機能していることを確認するには、nginxポートを公開してブラウザを使用してアクセスするか、コンテナ内の共有ディレクトリを直接確認します。

II-プロセス間通信(IPC)
ポッド内のコンテナは同じIPC名前空間を共有します。つまり、SystemVセマフォやPOSIX共有メモリなどの標準のプロセス間通信を使用して相互に通信することもできます。コンテナは、ポッド内の通信にローカルホスト名の戦略を使用します。
次の例では、2つのコンテナでポッドを定義します。両方に同じDockerイメージを使用します。最初のコンテナは、標準のLinuxメッセージキューを作成し、いくつかのランダムメッセージを書き込んでから、特別な終了メッセージを書き込むプロデューサーです。 2番目のコンテナは、同じメッセージキューを開いて読み取り、終了メッセージを受信するまでメッセージを読み取るコンシューマです。また、再起動ポリシーを「しない」に設定して、両方のコンテナの終了後にポッドが停止するようにしました。
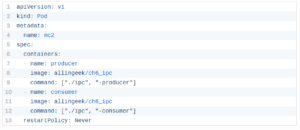
これを確認するには、kubectl createを使用してポッドを作成し、ポッドのステータスを確認します。

これで、各コンテナーのログを確認し、2番目のコンテナーが最初のコンテナーから終了メッセージを含むすべてのメッセージを受信したことを確認できます。
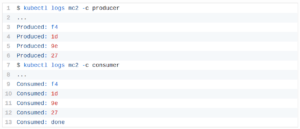
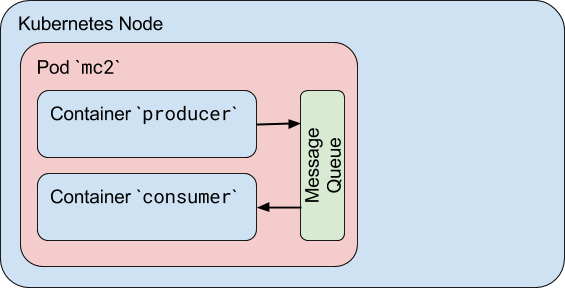
ただし、このポッドには1つの大きな問題があり、それはコンテナの起動方法に関係しています。
結論
ポッドが複数のコンテナーを持つことができる主な理由は、プライマリアプリケーションを支援するヘルパーアプリケーションをサポートするためです。ヘルパーアプリケーションの典型的な例は、データプラー、データプッシャー、およびプロキシです。このパターンの例は、新しい更新についてgitリポジトリをポーリングするヘルパープログラムを備えたWebサーバーです。
この演習のボリュームは、ポッドの存続期間中にコンテナが通信する方法を提供します。ポッドを削除して再作成すると、共有ボリュームに保存されているデータはすべて失われます。この記事では、共有ボリュームの概念の代替となる、ポッド内のコンテナー間のプロセス間通信の概念についても説明しました。ポッド内のコンテナがどのように通信してデータを交換できるかを学習したので、次に、ポッド間通信やポッド間通信など、他のKubernetesネットワーキングモデルについて学習します。 こちら Kubernetes開発に関するより高度なトピックを学ぶための良い記事です。