
By Bob Reselman
今日、エッジコンピューティングは、テクノロジーの世界では当たり前のことです。メタバースに入ることができるバーチャルリアリティヘッドセットであっても、POSシステムから交通機関の停車場での信号無視カメラまで、どこにでもあるように見えます。
一見すると、エッジコンピューティングはKubernetesに自然に適合しているように見えます。結局のところ、Kubernetesの強みは、共通のネットワークに接続された数千とは言わないまでも数百のノードに分散されたアプリケーションを簡単にサポートできるフレームワークであるということです。多くの場合、Kubernetesは確かにエッジコンピューティングに適していますが、そうでない場合もあります。この互換性、および潜在的な非互換性は、特にエッジコンピューティングとKubernetesの統合に関心のある開発者の場合は、検討する価値があります。
この記事では、エッジコンピューティングの基本の概要を簡単に説明し、エッジコンピューティングをKubernetesと統合する方法を検討します。メリットと目前の課題について見ていきます。無料で詳細を学ぶこともできます k3sを使用したKubernetesonEdgeの概要 CNCFおよびLinuxFoundationTraining&Certificationのオンライントレーニングコース。
まず、エッジコンピューティングとは何か、そうでないものを理解することから始めます。
エッジコンピューティングとは何ですか?
エッジコンピューティングは、ネットワークの「エッジ」で動作するハードウェアに計算処理アクティビティがプッシュされる技術アーキテクチャです。エッジコンピューティングは、ネットワーク上にあるデバイスが情報を収集し、それをリモートデータセンターに返して処理する集中型データ処理パターンの反対です。エッジコンピューティングでは、データを収集するデバイスで可能な限り多くの処理が実行されます。
エッジコンピューティングの良い例は、街の街角に配置された赤信号の交通カメラのコレクションです。赤信号の交通カメラには、車が交差点で赤信号を実行したことを検出するインテリジェンスを備えたコンピューターが組み込まれています。カメラは問題のある車両の写真を撮り、その写真を法執行機関に送信して確認します。 (下の図1を参照してください。)法執行機関が車が実際に赤信号を発していることを確認した場合、法執行機関は違反を発行します。
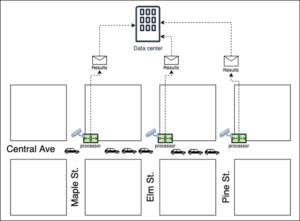
図1:赤信号の交通カメラには、車両による交通違反を特定し、結果を集約データセンターに転送できるインテリジェンスがあります。
交通を監視し、違反者を特定し、問題のあるイベントの写真を撮り、その写真とそのメタデータを法執行機関に転送するために必要なすべてのロジックが、交通カメラに組み込まれています。エッジデバイス(この場合は交通監視カメラ)は、その目的に関連する処理作業を吸収します。これがエッジコンピューティングの本質です。
別の方法は、交差点の瞬間的なスナップショットをリモートのデータセンターに継続的に送り返し、中央施設のインテリジェンスに分析作業を行わせることです。データセンター内のコンピューターは、ネットワークを介して届く各写真を分析して、交差点の赤信号を実行している車両を特定します。これは実行可能な代替手段ですが、最適な代替手段ではありません。ネットワークトラフィックだけでも圧倒される可能性があります。
本質的なメリットを理解する
上記の赤信号交通カメラのシナリオで示されているように、エッジコンピューティングの利点は、処理アクティビティをエッジに直接配置することで、デバイスネットワークトラフィックが削減され、システム全体の計算能力がより効率的になることです。
トレードオフは、エッジコンピューティングが増えると、デバイスでより多くの処理能力が必要になることです。 20年前は、違反者を検出するのに十分なほどスマートな赤信号の交通カメラを作ることは、大変な作業でした。必要な規模の小型化された計算能力は存在しませんでした。今日はそうです。携帯電話はデスクトップコンピュータの力を持っています。サイズが66.0mmx30.5mm x 5.0mm(2.56 in x 1.18 in x¼in)のRaspberry Pi Zeroは、ガムのパックの寸法で、交通カメラなどの小さなエッジデバイスに簡単に収まります。また、これらのデバイスはワイヤレスとBluetoothの両方に対応しているため、ネットワーク上での転送とセットアップが簡単です。コストは取るに足らないものです。 Raspberry Pi Zeroの小売価格は約$5ドルで、ピザの価格よりも安くなっています。
ただし、エッジデバイスが強力になるにつれて、エッジコンピューティングの実際の実装を可能にするための実行可能なアプリケーションフレームワークが必要になります。上記の信号無視のシナリオに戻ると、スタンドアロンの信号無視カメラは、信号無視を実行している車の写真を撮るだけではほとんど価値がありません。違反車両を検出して写真を撮る手段はありますが、違反者を報告するには、交通カメラがネットワークの一部である必要があります。また、交通カメラのソフトウェアを更新する簡単な方法が必要です。数千とは言わないまでも数百のデバイスが高価になり、最終的には管理できなくなる可能性がある都市でソフトウェア更新を行うために、技術者に各交通カメラを訪問するように要求します。幸い、Kubernetesは、エッジコンピューティングを効果的にサポートするために必要なタイプのパワーと柔軟性を提供します。
エッジでのKubernetesの使用
2015年のリリース以来、今では何年も前のように見えますが、Kubernetesは、Linuxコンテナーを使用して分散アプリケーションを実行するための主要なプラットフォームになっています。 Kubernetesには提供できるものがたくさんあります。スケーリングがよく、弾力性があり、非常に安全で、カスタマイズ可能です。アプリケーションをWebスケールで実行することを計画している場合、Kuberentesを使用しても解雇されることはありません。
ただし、エッジコンピューティングにKubernetesを使用する場合、Kubernetesをそのまま使用するのは難しい場合があります。まず、コントローラーノードとワーカーノードの両方のKubernetesソフトウェア自体が肥大化し、多くのディスクスペース、CPU、メモリを消費する可能性があります。また、ネットワーキングの問題もあります。箱から出してすぐに、Kubernetesはデータセンターを対象としたテクノロジーであることを忘れないでください。プレイ中のすべてのマシンが同じエリアにある場合に最適に機能します。ある地域にマシンを広め始めると、ネットワークは物理的にもソフトウェアの観点からも扱いにくいものになる可能性があります。
Kubernetesコミュニティのメンバーは、Kubernetesをエッジコンピューティングに適したプラットフォームにするために何かを行う必要があることに気づきました。それで彼らはそうしました。
現在、エッジコンピューティングスペース用に最適化されたKubernetesの2つの一般的な変更があります。 1つはK3Sで、もう1つはKubeEdgeです。 K3Sから始めて、両方を見てみましょう。
K3Sでの作業
K3Sは、Cloud Native Computing Foundation(CNCF)によって完全に認定されたKubernetesディストリビューションです。 K3Sは、Kubernetesの運用フットプリントのサイズをスリム化することで、Kubernetesをエッジコンピューティングで実行可能にすることを目的としています。 K3Sには 〜50 MBのディスク容量と〜300MBのRAMを使用 シングルノードクラスターを操作します。一方、 KubernetesのWebサイトで推奨 ノードあたり2GBのRAM。ストレージ要件は、Kubernetesクラスターの使用目的と構成によって異なります。ただし、必要なストレージ容量の一般的な見積もりについては、Red Hat 10GB以上を推奨 OpenShift製品のパーティション化されたディスクスペースまたはパーティション化されていないディスクスペース。
ご覧のとおり、K3Sは標準のKubernetesよりもはるかに小さいです。サイズの節約だけでも、K3Sはエッジデバイスでの作業に適しています。また、K3SはX86_64、ARM64、およびARMv7で動作します。 ARMサポートにより、RaspberryPIデバイスのファームを使用してK3Sクラスターを実行できます。これらのRaspberryPIデバイスは、センサーとカメラで構成できます。 Raspberry Piを車輪付きの電動シャーシに配置し、機動性を持たせれば、すぐに更新可能なモバイルデバイスのクラスターが倉庫やオフィスビルのホールをローミングし、すべてが単一のメインKubernetesサーバーによって管理されます。その意味は深いです。 K3Sはこれを可能にします。
K3Sクラスターの作成は、標準のKubernetesでのクラスターの作成と同様のプロセスです。まず、K3S用語ではサーバーと呼ばれるコントローラーをインストールします。次に、マシンをメインコントローラーに登録してノードを作成します。ノードで実行されるK3Sプロセスは、K3Sエージェントと呼ばれます。
K3Sサーバーをインストールするには、ホストマシンで次のコマンドを実行します。
curl -sfL https://get.k3s.io | sh –
上記のコマンドは、K3Sをダウンロードしてインストールします。サーバーのインストールプロセスでは、ワーカーノードがクラスターに参加するために必要なトークンも作成されます。トークンはファイルに保存されます: / var / lib / rancher / k3s / server / node-token
K3Sをエージェントとしてノードマシンにインストールし、そのマシンをクラスターに参加させるには、次のコマンドを実行します。
curl -sfL https://get.k3s.io | K3S_URL = :6443 K3S_TOKEN =sh –
どこ
- K3S_URL サーバーマシンのIPアドレスです
- K3S_TOKEN K3Sサーバーから取得したトークンです
K3Sエージェントが起動して実行されると、コントローラーとの接続を確立するトンネルプロキシがインストールされます。エージェントノードとコントローラーの間の情報は、プロキシを安全に通過します。 (下の図2を参照してください。)
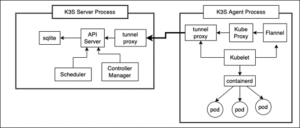
図2:K3Sエージェントノードは、トンネルプロキシを使用してメインコントローラーと通信します。
物事のコツをつかんだ後、K3Sクラスターのプロビジョニングは簡単な作業です。いくつかの落とし穴があります。たとえば、新しいバージョンの ラズビアン オペレーティングシステムは、Linuxコンテナをサポートするように構成されています。 (作成者のアドバイス:K3Sを新しい64ビットバージョンのRaspianで実行するには、少し調整する必要がありました。)
ただし、基本的に、K3のセットアップは、標準のKubernetesで行うプロセスと同様のプロセスです。サーバーをプロビジョニングし、ワーカーノードをプロビジョニングしてから、ワーカーノードをメインコントローラーノードに登録します。
物事がトリッキーになる可能性があるのは、クラスター内で実行される実際のアプリケーションの周りです。エッジコンピューティングに関しては、RaspberryPiマシンの束を展開してそのままにしておく企業はほとんどありません。エッジの力は、センサーやカメラから収集した情報の収集や処理など、単純なコンピューティングを超えたデバイス機能を使用することです。
特別な物理デバイス(センサーとカメラ)で構築されたハードウェアがある場合、ハードウェア上で実行されるアプリケーションは、インストールされているデバイスの操作方法を知っている必要があります。したがって、Kubernetesデプロイメントマニフェストファイルをどのように設定するかに注意を払う必要があります。たとえば、センサーを使用して室温情報を処理するアプリケーションが、カメラのみを備えたデバイスに展開されるような状況に陥りたくない場合があります。幸い、Kubernetesには ノードアフィニティ これにより、ノードの機能に応じてノードにラベルを付けることができます。これは、ノード上にあるハードウェアのタイプを宣言し、必要なハードウェアの詳細に従ってラベル付けされたターゲットノードに展開マニフェストを構成できることを意味します。たとえば、次のようにカメラを持つノードにラベルを付けることができます。
kubectl label pi-worker-01 device = camera
次に、以下に示すように、それに応じてデプロイメントマニフェストを構成します。 (yamlファイルのnodeAffinity属性の設定に注意してください。)
apiVersion:apps / v1
種類:展開
メタデータ:
名前:顔認識
ラベル:
アプリ:顔認識
仕様:
セレクタ:
matchLabels:
アプリ:顔認識
テンプレート:
メタデータ:
ラベル:
アプリ:顔認識
仕様:
親和性:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
– matchExpressions:
–キー:デバイス
演算子:で
値:
–カメラ
コンテナ:
–画像:顔認識
名前:顔認識
ポート:
– containerPort:8092
アプリケーションの展開を特定のハードウェア構成に限定することは、デバイスが実際にハードウェア上にある限り、目立たないものではありません。 Bluetoothを介してエッジノードと通信するリモートセンサーデバイスなど、エッジデバイスがノードから分離されている場合は、問題が発生する可能性があります。 K3Sアーキテクチャは、この状況をそのまま処理するのに苦労します。一方、KubeEdgeは、センサー、カメラ、その他のタイプのエッジデバイスがマザーボードに直接接続されていないエッジノードで動作するように設計されています。 KubeEdgeアーキテクチャは、エッジデバイスがホストハードウェアから分離されている状況をサポートすることを目的としています。見てみましょう。
KubeEdgeでの作業
KubeEdgeは、さまざまなエッジデバイスで実行される分散アプリケーションをサポートすることを目的としたオープンソースプロジェクトです。 K3と同様に、KubeEdgeはKubernetesの簡略版です。
KubeEdgeが機能する方法は、クラウドにメインコントローラーハブがあることです。エッジのノードは、他のノードがKuberenetesクラスターに参加するのと同じように、メインコントローラーに登録されます。ノードは、メインコントローラーにクラスターへの参加を要求します。ただし、管理がを使用して行われるKubernetesとは異なり、 クベアドム CLIツール、KubeEdgeの下で特別なものを使用します keadm 実行可能。
KubeEdgeのインストール
以下のコマンドラインの例でわかるように、メインコントローラーを起動して実行するのは簡単です。
keadm init –advertise-address =
次に、メインコントローラーが起動して実行されたら、次のようなトークンを要求します。
keadm gettoken
エッジノードをクラスターに登録するときに、そのトークンを使用します。エッジノードを登録するには、 keadm 目的のエッジノードマシンでCLIツールを実行し、次のコマンドを実行します。クラウドのメインコントローラーから以前にリクエストしたトークンです。
keadm join –cloudcore-ipport = –token =
この時点で、クラウドのメインコントローラーはエッジのワーカーノードを認識しています。分散クラスターがあります。エッジデバイスをエッジノードに統合するには、エッジコンピューティング環境でのデバイス管理のニュアンスに関係する別のレベルの構成が必要です。
接続されているデバイスと接続されていないデバイスの操作
デバイスをエッジで物理的に構成するには、2つの方法があります。
1つの方法は、エッジデバイスをホストコンピューターノードに直接インストールする場合です。たとえば、ビデオカメラをRaspberryPiのマザーボードに直接接続します。もう1つの方法は、デバイスがノードから分離されている場合です。たとえば、工場の天井に配置されたモーションディテクタなどです。モーションディテクタにはコンピューティングデバイスがインストールされていません。それができるのは信号を発することだけです。
K3Sは、エッジデバイスがRaspberryPiなどのホストコンピューターに直接接続されている場合に使用するのに適しています。 KubeEdgeは、エッジデバイスがホストコンピューターまたはネットワークに直接接続されていない状況に最適です。
KubeEdgeアーキテクチャには、という名前のコンポーネントがあります マッパー 非同期メッセージブローカーとして実行されるエージェントに組み込まれています。マッパーは MQTT。 MQTTは、IoTデバイス間の通信を可能にする軽量のメッセージングプロトコルです。 pub-subメッセージングパターン。下 マッパー、コンピューティングデバイスとIoTデバイス(たとえば、交通監視カメラ)の間の物理的な接続は、Bluetoothを介して確立されます。交通監視カメラは、Bluetooth接続を介してビデオストリームデータをマッパーに送信します。 Edge Coreという名前のエッジノード上のコンポーネントは、マッパーに送信されたメッセージを取得し、エッジノードで実行されているコンテナーに転送します。コンテナは、Edge Coreからのメッセージ(この場合は交通監視カメラからのビデオ信号)を処理するロジックを備えたアプリケーションをホストします。
図3に示すように、KubeEdgeで実行されるエッジアーキテクチャは、デバイスとエッジノード間の1対1の関係で構成できます。
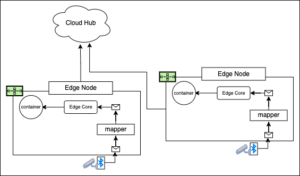
図3:KubeEdgeは、ノードごとに1つのデバイスをサポートするように構成できます。
アーキテクチャを構成する別の方法は、図4に示すように、エッジノードにインストールされている多くのアプリケーションが単一のデバイスから送信されるメッセージを消費するようにすることです。
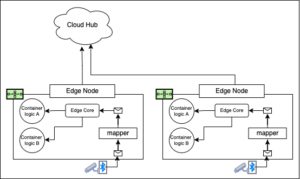
図4:単一のデバイスからデータを消費する多くのアプリケーションを実行しているエッジノード。
さらに、エッジノードは、以下の図5に示すように、1つ(または多くのアプリケーション)がマッパーコンポーネントに接続された多くのデバイスからのメッセージを消費するように構成できます。
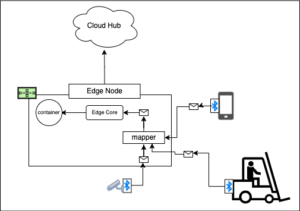
図5:また、KubeEdgeは、ノードごとに複数のデバイスをサポートするように構成できます。
KubeEdgeで興味深いのは、デバイス構成が静的ではないことです。 Bluetooth経由でMapperとペアリングし、クラスター内のアプリケーションが理解できるメッセージを送信できる限り、どのデバイスもいつでもクラスターに参加できます。
KubeEdgeに関して理解しておくべき重要なことは、エッジデバイスが対応する計算ロジックを含むノードから分離されている状況をサポートできるということです。
ただし、K3SとKubeEdgeが提供するすべての利点には、まだ欠点があります。驚いたことに、これらの欠点の多くは、K3SとKubeEdgeの詳細とはほとんど関係がありません。むしろ、問題はエッジコンピューティングとKubernetes全体の性質に関するものです。
エッジでKubernetesを使用する際の2つの基本的な課題を理解する
K3SとKubeEdgeはどちらも、エッジコンピューティングの採用を容易にするテクノロジーです。しかし、テクノロジーと同じくらい強力であるため、それらは万能薬ではありません。次のセクションでは、エッジでKuberentesを使用する場合の2つの基本的な課題について説明します。
ほとんどのエッジコンピューティングシナリオでは、レプリケーションと冗長性は無関係になります
Kubernetesの重要な価値提案の1つは、アプリケーションのレプリケーションと冗長性を自動化することです。 Kubernetes 展開 と ReplicaSets プロジェクトの初期から存在しています。ポッドが デプロイ または ReplicaSet ダウンすると、Kubernetesのインテリジェンスは、障害が発生したポッドを復活させるか、代わりに新しいポッドを作成しようとします。また、Kubernetesサービスで実行されている同一のポッドのデプロイでは、負荷分散が自動的に行われます。レプリケーションと冗長性の組み込みサポートにより、Kuberenetesは、汎用ノードでいっぱいのデータセンターで実行することを目的としたアプリケーションにとって魅力的なテクノロジーになります。ただし、エッジコンピューティングは異なります。エッジで実行されているノードは一般的ではなく、特定のものです。
交通カメラを実行しているノードは、クレジットカードリーダーを実行しているノードとは大きく異なります。そのため、レプリケーションと冗長性は無関係になります。
考えてみてください。
街角の交通カメラの冗長性を確保する唯一の方法は、バックアップカメラがプライマリカメラのすぐ横に設置されていることを確認することです。クレジットカードリーダーも同様です。食料品店のチェックアウトカウンターに立っていて、クレジットカードリーダーが故障したとします。誰かがバックオフィスから不足して来て、新しいリーダーを接続しますか?ありそうもない。おそらく、リーダーが機能している別のチェックアウトカウンターに行くように言われます。レプリケーションと冗長性は、デバイスレベルではなく、チェックアウトカウンターのレベルに存在します。特定のチェックアウトカウンターでは、エッジデバイス間にレプリケーションと冗長性はありません。
エッジにレプリケーションと冗長性がないため、エッジ用の分散アプリケーションを作成する人は少し違った考え方をする必要があります。エッジコンピューティングはより現実的な世界です。デバイスがダウンした場合、オンラインでの復旧はデータセンターほど簡単ではありません。 Kuberenetesに、ロジックを実行するために近くのラックにある別のコンピューターを探すように指示することはできません。エッジコンピューティングでは、ロジックは物理デバイスに非常に緊密にバインドされており、そのデバイスに障害が発生した場合、通常、そのデバイスの復元には何らかの物理的介入が必要です。
要点は次のとおりです。エッジコンピューティングの世界では、アーキテクトは、Kuberentes、K8S、KubeEdgeのいずれを実行していても、現実の世界を歩き続ける必要があります。
何があっても、Linuxコンテナマネージャーが必要です
RaspberryPiでK3SまたはKubeEdgeを実行するのは自然なことです。 Raspianオペレーティングシステムは、Kubernetesをインストールして実行するために必要なすべてのものに対応できます。ただし、iOSまたはAndroidデバイスでK3SまたはKubeEdgeのいずれかを実行することは、実際の課題になる可能性があります。私は知っています、私はそれを試しました。
ありふれたLinuxディストリビューションを実行しているコモディティX86およびARMマシンでの作業を当然のことと思っているものはすべて、iOSおよびAndroidの世界では贅沢です。パッケージマネージャーにアクセスしたり、ファイルシステムにルートアクセスしたりするのと同じくらい一般的なことでさえ、携帯電話やタブレットで作業する場合は重要な雑用です。
コンテナを実行したい場合、事態はさらに複雑になります。コンテナはオペレーティングシステムに深く結びついています。目的のエッジノードにライブラリが1つ欠けていると、プログラミングに多くの問題が発生する可能性があります。
要点は次のとおりです。エッジデバイスをKubernetesクラスターで実行するには、どのような場合でも、そのデバイスは最小限の労力でLinuxコンテナーを実行できる必要があります。それができない場合は、ある種のデータコレクターと通信するHTTPクライアントが組み込まれているデバイス用のカスタムエージェントを作成することをお勧めします。
将来的には、Linuxコンテナーは、キッチンの冷蔵庫やポケットの携帯電話で実行できるようになる可能性がありますが、その時が来るまでは、試行錯誤された実装を使用して、エッジでKubernetesを実行することをお勧めします。
すべてを一緒に入れて
エッジコンピューティングはゲームチェンジャーです。何百万もの独立したデバイスを一緒に調整して、事前定義された目標に向けて協調して行動できることは、重要な技術的成果です。それも難しい仕事です。幸い、Kubernetes全般、特にK3SやKubeEdgeなどのプロジェクトは、この規模のビジョンを、野心を持ち、すべてを実現するために時間を費やすことをいとわない開発者にとって実現可能にすることができます。それは欲望の問題です。
ウェブサイトStatistaによると、エッジコンピューティング市場は 2025年までに2740億ドルに成長する。このタイプの成長は、エッジコンピューティングのダイナミクスに精通しているエンジニアに大きなチャンスをもたらします。エッジでKubernetesを使用して今日実践的な経験を積むことは、将来大きな見返りがあります。
このトピックについて学び続けるには、無料のチェックアウトしてください k3sを使用したKubernetesonEdgeの概要 CNCFおよびLinuxFoundationTraining&Certificationのオンライントレーニングコース。