
By Bob Reselman
Today edge computing is commonplace on the technology landscape. It seems as if it’s everywhere, from point of sale systems to red-light cameras at traffic stops, even in the virtual reality headsets that allow entry into the metaverse.
At first glance it seems as if edge computing is a natural fit for Kubernetes. After all, Kubernetes’s strength is that it’s a framework that can easily support applications that are distributed over hundreds if not thousands of nodes connected on a common network. In many cases Kubernetes is indeed well suited for edge computing, but in some cases it’s not. This compatibility – and as well as potential incompatibilities – are worth examining, particularly if you are a developer interested in integrating edge computing with Kubernetes.
In this article I am going to present a brief overview of the essentials of edge computing and examine how edge computing can be integrated with Kubernetes. I am going to look at the benefits as well as the challenges at hand. You can also learn more in the free Introduction to Kubernetes on Edge with k3s online training course from CNCF and Linux Foundation Training & Certification.
The place to start is with an understanding of what edge computing is and what it is not.
What is Edge Computing?
Edge computing is a technical architecture in which computational processing activity is pushed onto the hardware operating on the “edge” of the network. Edge computing is the opposite of the centralized data processing pattern in which devices out on the network gather information and pass it back to a remote data center for processing. Under edge computing, as much processing as possible gets executed on the devices gathering the data.
A good example of edge computing is a collection of red-light traffic cameras positioned on a city’s street corners. A red-light traffic camera has a built-in computer that has the intelligence to detect when a car runs a red-light at a traffic intersection. The camera will take a photo of the offending vehicle and then send that photo onto a law-enforcement agency for verification. (See Figure 1, below.) If a law-enforcement agent verifies that the car has indeed run the red light, the agency will issue a violation.
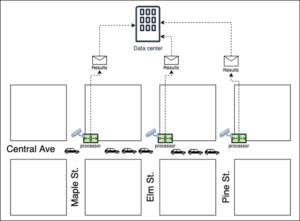
Figure 1: Red-light traffic cameras have intelligence that can determine moving violations by vehicles and forward results onto an aggregating data center.
All the logic needed to observe traffic, identify violators, take a photo of the offending event and then forward the photo and its metadata onto a law enforcement agency is built into the traffic camera. The edge device, in this case the traffic camera, absorbs the processing labor associated with its purpose. This is the essence of edge computing.
The alternative would be to continuously send momentary snapshots of the intersection back to a remote data center and then have intelligence in the central facility do the analysis work. Computers in the data center would analyze each photo coming over the network to determine vehicles running the intersection’s red-light. It’s a viable alternative, but not an optimal one; the network traffic alone could be overwhelming.
Understanding the Essential Benefits
As demonstrated in the red-light traffic camera scenario described above, the benefit of edge computing is that by putting processing activity directly at the edge, device network traffic is reduced and the computational power of the system overall is more efficient.
The tradeoff is that more edge computing requires more processing power on the device. Twenty years ago making a red-light traffic camera smart enough to detect violators would have been a herculean task. Miniaturized computing power of the magnitude needed didn’t exist; today it does. Cellphones have the power of a desktop computer. A Raspberry Pi Zero which measures 66.0mm x 30.5mm x 5.0mm (2.56 in x 1.18 in x ¼ in) in size, the dimensions of a pack of gum, can fit easily into a small edge device such as a traffic camera. And, those devices are both wireless and bluetooth enabled making them easy to transport and set up on a network. Costs can be trivial. A Raspberry Pi Zero retails for around $5 dollars, less than the price of a pizza.
However, for as powerful as edge devices are becoming, you need a viable application framework to make real world implementation of edge computing possible. Going back to the traffic light scenario described above, a standalone red-light camera has little value if all it can do is take pictures of cars running a red light. Even though it has the wherewithal to detect and photograph offending vehicles, the traffic camera still needs to be part of a network in order to report violators. Also, there needs to be an easy way to update the software on the traffic cameras. Requiring a technician to visit each traffic camera to do a software update in a city that might have hundreds, if not thousands of such devices can become expensive and eventually unmanageable. Fortunately Kubernetes provides the type of power and flexibility needed to support edge computing effectively.
Using Kubernetes at the Edge
Since its release in 2015 – which now seems like eons ago – Kubernetes has become the predominant platform for running distributed applications using Linux containers. Kubernetes has a lot to offer. It scales well, it’s resilient, it can be very secure and it’s customizable. If you plan to run your application at web scale, you won’t get fired for using Kuberentes.
However, when it comes to using Kubernetes for edge computing, using Kubernetes out of the box can be tricky. First of all, the Kubernetes software itself, both for controller and worker nodes can get bloated and take up a lot of disk space, CPU and memory. And also there is the issue of networking. Remember, out of the box Kubernetes is technology targeted at the data center. It works best when all the machines in play are in the same area. When you start spreading machines over a geography, networking can get tricky both physically and in terms of the software.
Members of the Kubernetes community realized that something needed to be done to make Kubernetes an appropriate platform for edge computing. So they did.
Presently there are two popular modifications of Kubernetes optimized for the edge computing space. One is K3S and the other is KubeEdge. Let’s take a look at them both, starting with K3S.
Working with K3S
K3S is a Kubernetes distribution fully certified by the Cloud Native Computing Foundation (CNCF). K3S is intended to make Kubernetes viable for edge computing by slimming down the size of the Kubernetes operational footprint. K3S requires ~50 MB of disk space and uses ~300 MB of RAM to operate a single node cluster. On the other hand, the Kubernetes website recommends 2 GB of RAM per node. Storage requirements will vary according to the intended use and configuration of the Kubernetes cluster. Yet, for a general estimate of storage capacity required, Red Hat recommends a minimum of 10 GB of partitioned or unpartitioned disk space for its OpenShift product.
As you can see, K3S is much smaller than standard Kubernetes. The size savings alone makes K3S appropriate for working with edge devices. Also, K3S runs on X86_64, ARM64 and ARMv7. ARM support makes it possible to run a K3S cluster using a farm of Raspberry PI devices. Those Raspberry PI devices can be configured with sensors and cameras. Put the Raspberry Pi on a motorized chassis with wheels and have mobility, and in no time at all you have a cluster of updatable mobile devices roaming the halls of a warehouse or office buildings with all managed by a single main Kubernetes server. The implications are profound. K3S makes this possible.
Creating a K3S cluster is a process similar to creating one in standard Kubernetes. First you install the controller, which in K3S parlance is called a server. Then, you create nodes by registering machines with the main controller. The K3S process that runs on the node is known as a K3S agent.
To install the K3S server you execute the following command on the host machine:
curl -sfL https://get.k3s.io | sh –
The command above will download and install K3S. The server installation process also creates a token that worker nodes need to join the cluster. The token will be stored in the file: /var/lib/rancher/k3s/server/node-token
To install K3S as an agent on a node machine and have that machine join the cluster, execute the following command:
curl -sfL https://get.k3s.io | K3S_URL=<HOST_IP_ADDRESS>:6443 K3S_TOKEN =<TOKEN> sh –
WHERE
- K3S_URL is the IP address of the server machine
- K3S_TOKEN is the token retrieved from the K3S server
Once the K3S agent is up and running it will have a tunnel proxy installed that will establish a connection with the controller. Information to and from the agent node to the controller will pass securely through the proxy. (See Figure 2, below.)
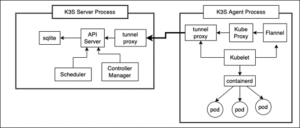
Figure 2: A K3S agent node uses a tunnel proxy to communicate with the main controller.
After you get the hang of things, provisioning a K3S cluster is a straightforward undertaking. There are few gotchas, for example making sure that newer versions of the Raspbian operating system are configured to support Linux containers. (Author advisory: I had to do a bit of twiddling to get K3S to run on the new 64 bit version of Raspian.)
Yet essentially, setting up K3s is a process similar to the one you do with standard Kubernetes: you provision the server, provision worker nodes and then register the worker nodes to the main controller node.
Where things can get tricky is around the actual applications that will be running within the cluster. When it comes to edge computing, few companies are just going to deploy a bunch of Raspberry Pi machines and leave it at that. The power of edge is about using device capabilities that go beyond simple computing, for example collecting and processing information gathered from sensors and cameras.
When you have hardware that’s constructed with special physical devices – again, sensors and cameras – the applications that run on the hardware need to know how to work with the devices installed. Thus, you need to pay attention to how you configure the Kubernetes deployment manifest files. For example, you don’t want to end up with situations in which an application that processes room temperature information using sensors ends up being deployed on a device that has only a camera. Fortunately Kubernetes has a concept called node affinity that allows you to label nodes according to their capability. This means that you can declare the type of hardware that’s on a node and configure a deployment manifest to target nodes labeled according to the hardware specifics required. For example, you can label a node that has a camera like so:
kubectl label pi-worker-01 device=camera
And then configure the deployment manifest accordingly as shown below. (Notice the settings in the nodeAffinity attribute of the yaml file.)
apiVersion: apps/v1
kind: Deployment
metadata:
name: face-recognition
labels:
app: face-recognition
spec:
selector:
matchLabels:
app: face-recognition
template:
metadata:
labels:
app: face-recognition
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
– matchExpressions:
– key: device
operator: In
values:
– camera
containers:
– image: face-recognition
name: face-recognition
ports:
– containerPort: 8092
Confining application deployments to a specific hardware configuration is not a show stopper as long as the device is actually on a piece of hardware. Things can get tricky when the edge device is separate from the node, such as a remote sensor device that communicates to an edge node via Bluetooth; the K3S architecture will have a hard time handling this situation out of the box. On the other hand, KubeEdge is designed to work with edge nodes that do not have sensors, cameras and other types of edge devices attached directly to the motherboard. The KubeEdge architecture is intended to support situations in which an edge device is separate from the host hardware. Let’s take a look.
Working with KubeEdge
KubeEdge is an open source project intended to support distributed applications running with a variety of edge devices. As with K3s, KubeEdge is a stripped down version of Kubernetes.
The way that KubeEdge works is that there is a main controller hub in the cloud. Nodes at the edge register themselves to the main controller very much in the same way any node joins a Kuberenetes cluster. The node asks the main controller to join the cluster. However, unlike Kubernetes where administration is conducted using the kubeadm CLI tool, under KubeEdge you’ll use a special keadm executable.
Installing KubeEdge
Getting the main controller up and running is straightforward, as you can see in the command line example below.
keadm init –advertise-address=<HOST_IP_ADDRESS>
Then, once the main controller is up and running, you’ll ask it for a token like so:
keadm gettoken
You’ll use that token when registering an edge node to the cluster. You register an edge node by installing the keadm CLI tool on the intended edge node machine and then execute the following command where <TOKEN> is the token you requested previously from the main controller in the cloud.
keadm join –cloudcore-ipport=<HOST_IP_ADDRESS> –token=<TOKEN>
At this point the main controller in the cloud knows about its worker nodes at the edge. You have a distributed cluster. Integrating an edge device to an edge node requires another level of configuration which has to do with the nuance of device management in an edge computing environment.
Working with attached and unattached devices
There are two ways that a device can be physically configured at the edge.
One way is where an edge device is installed directly on the host computer node, for example a video camera connected directly to a Raspberry Pi’s motherboard. Another way is when the device is separated from the node, for example a motion detector placed in the ceiling in a factory. The motion detector has no computing device installed; all it can do is emit signals.
K3S is appropriate to use when the edge device is directly attached to a host computer such as a Raspberry Pi. KubeEdge is a good fit for those situations in which the edge device has no direct connection to a host computer or a network.
The KubeEdge architecture has a component named Mapper built into the agents that runs as an asynchronous message broker. Mapper uses MQTT. MQTT is a lightweight messaging protocol that enables communication between IoT devices using the pub-sub messaging pattern. Under Mapper, the physical connection between a computing device and the IoT device – a traffic camera, for example – is established via Bluetooth. The traffic camera sends its video stream data to Mapper via the Bluetooth connection. A component on the edge node named Edge Core picks up the messages sent to Mapper and forwards them onto a container running in the edge node. The container hosts an application that has logic to process messages coming in from Edge Core, in this case the video signal coming from the traffic camera.
An edge architecture running under KubeEdge can be configured with a relationship between device and edge node that is one-to-one as shown in Figure 3.
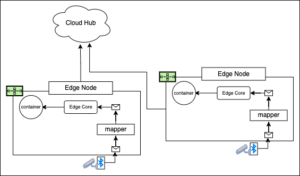
Figure 3: KubeEdge can be configured to support one device per node.
Another way to configure the architecture is to make it so that many applications installed on the edge node are consuming messages coming out of a single device as shown in Figure 4.
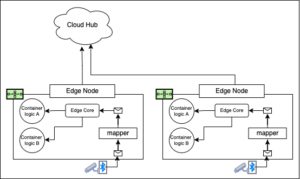
Figure 4: An edge node with running many applications consuming data from a single device.
In addition, the edge node can be configured so that one (or many applications) are consuming messages coming from many devices connected to the Mapper component as shown below in Figure 5.
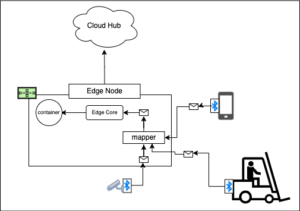
Figure 5: Also, KubeEdge can be configured to support multiple devices per node.
What’s also interesting under KubeEdge is that device configuration is not static. Any device can join the cluster at any time as long as it can pair up with Mapper via Bluetooth and emit messages that are understandable to applications in the cluster.
In terms of KubeEdge, the important thing to understand is that it can support situations in which the edge device is separate from the node that contains the corresponding computational logic.
However, for all the benefits that K3S and KubeEdge provide, there are still shortcomings. Surprisingly, many of these shortcomings have little to do with the specifics of K3S and KubeEdge. Rather the issues are about the nature of edge computing and Kubernetes overall.
Understanding the two fundamental challenges of using Kubernetes at the edge
Both K3S and KubeEdge are technologies that make adopting edge computing easier. But, for as powerful as the technologies are, they are not a panacea. The following sections describe two fundamental challenges that go with using Kuberentes at the edge.
Replication and redundancy become irrelevant in most edge computing scenarios
One of the essential value propositions for Kubernetes is that it automates application replication and redundancy. Kubernetes Deployments and ReplicaSets have been around since the early days of the project. When a pod running under a Deployment or a ReplicaSet goes down, intelligence in Kubernetes will try to resurrect the failing pod or create a new one in its place. Also, a deployment of identical pods running under a Kubernetes service gets load balanced automatically. Built-in support for replication and redundancy make Kuberenetes a compelling technology for applications that are intended to run in a data center full of generic nodes. However, edge computing is different. Nodes running at the edge are not generic, rather they are specific.
A node running a traffic camera is much different than a node running a credit card reader. As such, replication and redundancy become irrelevant.
Think about it.
The only way to ensure redundancy for a traffic camera on a street corner is to make sure that a backup camera is installed right beside the primary camera. Same with a credit card reader. Imagine you’re standing at the checkout counter in a grocery store and the credit card reader fails. Does someone come running out from the back office and hook up a new reader? Not likely. You’re probably told to go to another checkout counter that has a functioning reader. Replication and redundancy exists at the level of the checkout counter not at the device level. There is no replication and redundancy among the edge devices at the given checkout counter.
The absence of replication and redundancy at the edge requires those creating distributed applications for the edge to think a bit differently. Edge computing is more real world; when devices go down, getting them back up online is not as easy as it is in the data center. You simply can’t tell Kuberenetes to go find another computer on a nearby rack on which to run logic. In edge computing the logic is very tightly bound to the physical device and when that device fails, restoring it usually involves some sort of physical intervention.
The takeaway is this: in the world of edge computing, architects need to keep on foot in the real world whether they’re running Kuberentes, K8S or KubeEdge.
No matter what, you need a Linux container manager
Running K3S or KubeEdge on Raspberry Pi is a natural fit. The Raspian operating system can accommodate all the things needed to get Kubernetes installed and running. However, running either K3S or KubeEdge on an iOS or Android device can be a real challenge. I know, I’ve tried it.
All the things we take for granted working on commodity X86 and ARM machines running commonplace Linux distros are luxuries in the iOS and Android world. Even something as typical as having access to a package manager and getting root access to the file system are significant chores when working with a cell phone or tablet.
Things get even more complex when you want to run a container. Containers are deeply bound to the operating system. One missing library on the intended edge node can cause a lot of programming pain.
The takeaway is this: for any edge device to run in a Kubernetes cluster, no matter what, that device needs to be able to run Linux containers with a minimum of effort. If it can’t, you’re better off writing a custom agent for the device that has an HTTP client built in that communicates back to some type of data collector.
In the future Linux containers might be able to run on the refrigerator in your kitchen or the cell phone in your pocket, but until that time comes, it’s better to run Kubernetes at the edge using implementations that are tried and true.
Putting it all together
Edge computing is a game changer. Being able to orchestrate millions of independent devices together to act in concert toward a predefined goal is a significant technical achievement. It’s also a difficult undertaking. Fortunately Kubernetes in general and projects such as K3S and KubeEdge in particular can make a vision of this scale feasible to any developer who has the ambition and is willing to invest the time to make it all come true. It’s a matter of desire.
According to the website Statista, the edge computing market is anticipated to grow to 274 billion dollars by 2025. This type of growth presents significant opportunities for those engineers well versed in the dynamics of edge computing. Getting hands-on experience today working with Kubernetes at the edge will have big payoffs in the future.
To continue learning about this topic, check out the free Introduction to Kubernetes on Edge with k3s online training course from CNCF and Linux Foundation Training & Certification.